



Data Lake Security with Imperva
News | 25.07.2023
A data lake serves as a central repository used for storing several types of data, at scale. For example, you can store unstructured data, as well as structured data, in your data lake.
A data lake does not require any upfront work on the data. You can simply integrate and store data as it streams in from multiple sources. Depending on the capabilities of the system you are using, you might be able to set up real-time data ingestion.
Organizations typically use data lakes to store data for future or real-time analysis. This often requires the use of analytics tools and frameworks, like Google BigQuery, Amazon Athena, or Apache Spark.
A data lake can have various types of physical architectures because it can be implemented using many different technologies. However, there are three main principles that differentiate a data lake from other big data storage methods:
- All data is accepted to the data lake—it ingests and archives data from multiple sources, including structured, unstructured, raw, and processed data.
- Data is stored in its original form—after receiving the data from the source, the data is stored unconverted or with minimal treatment.
- Data transformed on demand—the data is transformed and structured according to the analysis requirements and queries being performed.
Most of the data in a data lake is unstructured and not designed to answer specific questions, but it is stored in a way that facilitates dynamic querying and analysis.
Regardless of how you choose to implement a data lake, the following capabilities will help you keep it functional and make good use of its unstructured data:
- Data classification and data profiling — the data lake should make it possible to classify data, by data types, content, usage scenarios, and possible user groups. It should be equipped with data profiling technology, to provide insights into data quality.
- Conventions — the data lake should, as much as possible, enforce agreed file types and naming conventions.
- Data access — there should be a standardized data access process, used both by human users and integrated systems, which enables tracking of access and use of the data.
- Data catalog — the data lake should provide a data catalog that enables the search and retrieval of data according to a data type or usage scenario.
- Data protection — security controls, data encryption, and automatic monitoring must be in place, and alerts should be raised when unauthorized parties access the data, or when authorized users perform suspicious activities.
- Data governance — there should be clear policies, communicated to all relevant employees, about how to navigate and make use of the data lake, how to promote data quality, and ethical use of sensitive data.
Data lake analytics enables on-demand analytics on large volumes of data. You can generate valuable insights from data, without requiring a complex infrastructure to pre-process and organize your data.
A few common uses of data lake analytics are:
- Interactive analytics—derive specific insights from data, directly from a data lake, using a high-performance query engine like Google BigQuery or Amazon Athena.
- Big data processing—analyze large volumes of data using tools like Spark or Hadoop.
- Real-time analytics—process streams of data as they flow into the data lake in near-real-time, using stream processing tools like Apache Kafka.
- Operational analytics—search, filter, and visualize data from logs and operational data, such as web analytics or internet of things (IoT) logs, using tools like Elasticsearch.
Data Warehouse vs Data Lake?
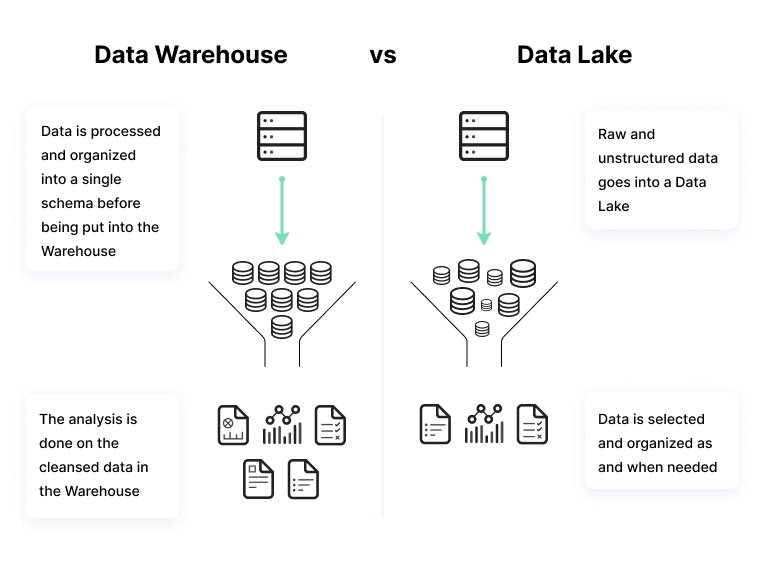
A data warehouse is a repository of data collected and generated by business applications. The data warehouse applies a predefined schema to the data before storing it. You need to organize and organize data before storing it in the warehouse.
Data warehouses are used to store large amounts of structured data from production systems, which needs to be regularly analyzed or is used to produce periodical reports. Data warehouses are usually the “source of truth” of the organization because they store organized and classified historical data.
Data lakes store data from many sources—including unstructured sources like log data, internet of things (IoT) sensors, and social media feeds. A data lake platform is basically a collection of raw data assets that come from an organization’s business operations and other sources, both internal and external.
Data in the data lake is highly heterogeneous and may require additional processing to be useful, making it unsuitable for the average business analytics user. However, data lakes can be extremely useful for more sophisticated users, such as data scientists and advanced data analysts.
The following best practices can help you make better use of a data lake in your organization:
Data Governance and Access Control
Data lakes raise major security concerns because they contain many different types of data, some of which may be sensitive or have compliance requirements. Because there are no database tables, permissions are more fluid and difficult to set up and must be based on specific objects or metadata definitions.
However, today this problem can be easily solved, and various governance tools can be used to control who has access to the data. Data catalog solutions allow users to create a catalog of the data, specifying different types of data and the access controls and storage policies for each.
Store Several Copies of Data
One of the main reasons for adopting a data lake is because it stores unstructured data and separates storage from computing, allowing you to store large amounts of data with a relatively small investment. Data lakes are commonly used to store both raw and processed data. In addition to this historical data, there is data that has undergone processing and was used in analytical workflows. This data must also be stored to enable future analysis and as a basis for reports and dashboards.
A data lake lets you store several copies of your data, each of which can have other potential uses.
Set a Retention Policy
A data lake commonly stores historical data, but no data should be stored forever. Data must be disposed of when no longer needed, both to conserve storage, and due to the requirements of compliance standards, such as the EU GDPR, California CCPA, and Australian APP.
There must be a convenient technical method to separate data you want to delete from the data you want to keep. Locating the data across the data lake storage architecture, which can include storage services like Amazon S3, HDFS, and block storage devices, can be challenging. Data catalog solutions can help with this challenge as well, providing a central interface that can classify data according to desired retention periods.
Imperva provides activity monitoring for relational databases, data warehouses, and data lakes, generating real-time alerts on anomalous activity and policy violations.
In addition to data lake security, Imperva protects all cloud-based data stores to ensure compliance and preserve the agility and cost benefits you get from your cloud investments.
Imperva capabilities include:
- Cloud Data Security – Simplify securing your cloud databases to catch up and keep up with DevOps. Imperva’s solution enables cloud-managed services users to rapidly gain visibility and control of cloud data.
- Database Security – Imperva delivers analytics, protection, and response across your data assets, on-premise and in the cloud – giving you the risk visibility to prevent data breaches and avoid compliance incidents. Integrate with any database to gain instant visibility, implement universal policies, and speed time to value.
- Data Risk Analysis – Automate the detection of non-compliant, risky, or malicious data access behavior across all of your databases enterprise-wide to accelerate remediation.
Receive a personal consultation on Imperva solutions from certified Softprom specialists.
Softprom - Value Added Distributor Imperva.
Share:


