



Data Lake Security von Imperva
News | 02.08.2023
Ein Data Lake dient als zentrales Repository für die Speicherung verschiedener Datentypen in großem Umfang. Beispielsweise können Sie in Ihrem Data Lake sowohl unstrukturierte als auch strukturierte Daten speichern.
Ein Data Lake erfordert keine Vorarbeiten an den Daten. Sie können Daten einfach integrieren und speichern, wenn sie aus verschiedenen Quellen einfließen. Je nach den Möglichkeiten des von Ihnen verwendeten Systems können Sie möglicherweise eine Datenaufnahme in Echtzeit einrichten.
Unternehmen nutzen Data Lakes in der Regel, um Daten für zukünftige oder Echtzeit-Analysen zu speichern. Dies erfordert häufig den Einsatz von Analysetools und Frameworks wie Google BigQuery, Amazon Athena oder Apache Spark.
>
Ein Data Lake kann verschiedene Arten von physischen Architekturen haben, da er mit vielen verschiedenen Technologien implementiert werden kann. Es gibt jedoch drei Hauptprinzipien, die einen Data Lake von anderen Big-Data-Speichermethoden unterscheiden:
- Alle Daten werden in den Data Lake aufgenommen - es werden Daten aus verschiedenen Quellen aufgenommen und archiviert, einschließlich strukturierter, unstrukturierter, roher und verarbeiteter Daten.
- Daten werden in ihrer ursprünglichen Form gespeichert - nach Erhalt der Daten von der Quelle werden die Daten unkonvertiert oder mit minimaler Bearbeitung gespeichert.
- Daten werden bei Bedarf transformiert - die Daten werden entsprechend den Analyseanforderungen und den durchgeführten Abfragen transformiert und strukturiert.
Die meisten Daten in einem Data Lake sind unstrukturiert und nicht für die Beantwortung spezifischer Fragen bestimmt, aber sie werden so gespeichert, dass eine dynamische Abfrage und Analyse möglich ist.
Unabhängig davon, wie Sie einen Data Lake implementieren, helfen Ihnen die folgenden Fähigkeiten, ihn funktionsfähig zu halten und seine unstrukturierten Daten sinnvoll zu nutzen:
- Datenklassifizierung und Datenprofilierung - der Data Lake sollte es ermöglichen, Daten nach Datentypen, Inhalten, Nutzungsszenarien und möglichen Nutzergruppen zu klassifizieren. Er sollte mit Datenprofilierungstechnologie ausgestattet sein, um Einblicke in die Datenqualität zu ermöglichen.
- Konventionen - der Data Lake sollte so weit wie möglich vereinbarte Dateitypen und Namenskonventionen durchsetzen.
- Datenzugriff - es sollte ein standardisiertes Datenzugriffsverfahren geben, das sowohl von menschlichen Nutzern als auch von integrierten Systemen verwendet wird und die Verfolgung des Zugriffs und der Nutzung der Daten ermöglicht.
- Datenkatalog - der Data Lake sollte einen Datenkatalog bereitstellen, der die Suche und den Abruf von Daten nach einem Datentyp oder einem Nutzungsszenario ermöglicht.
- Datenschutz - Sicherheitskontrollen, Datenverschlüsselung und automatische Überwachung müssen vorhanden sein, und es sollten Alarme ausgelöst werden, wenn Unbefugte auf die Daten zugreifen oder wenn autorisierte Benutzer verdächtige Aktivitäten durchführen.
- Data Governance - es sollte klare Richtlinien geben, die allen relevanten Mitarbeitern mitgeteilt werden, wie der Data Lake zu navigieren und zu nutzen ist, wie die Datenqualität zu fördern ist und wie der ethische Umgang mit sensiblen Daten aussieht.
Data Lake Analytics ermöglicht On-Demand-Analysen für große Datenmengen. Sie können wertvolle Erkenntnisse aus Daten generieren, ohne dass eine komplexe Infrastruktur zur Vorverarbeitung und Organisation Ihrer Daten erforderlich ist.
Einige häufige Verwendungszwecke von Data-Lake-Analysen sind:
- Interaktive Analysen: Gewinnen Sie mithilfe einer leistungsstarken Abfrage-Engine wie Google BigQuery oder Amazon Athena spezifische Erkenntnisse aus Daten direkt aus einem Data Lake.
- Big Data-Verarbeitung - Analyse großer Datenmengen mit Tools wie Spark oder Hadoop.
- Echtzeit-Analysen: Verarbeiten Sie Datenströme, die in den Data Lake fließen, nahezu in Echtzeit mit Stream-Processing-Tools wie Apache Kafka.
- Operative Analysen: Durchsuchen, filtern und visualisieren Sie Daten aus Protokollen und operativen Daten, wie z. B. Webanalysen oder Internet-of-Things (IoT)-Protokolle, mit Tools wie Elasticsearch.
Data Warehouse vs. Data Lake?
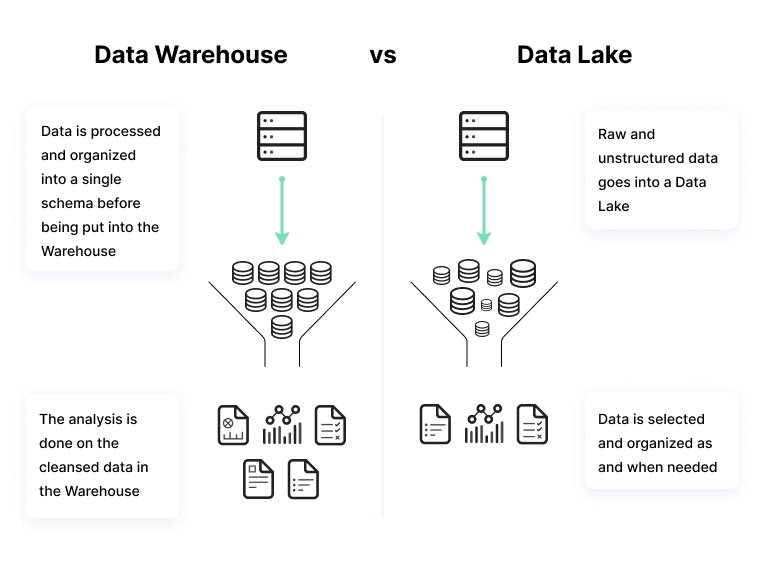
Ein Data Warehouse ist ein Repository für Daten, die von Geschäftsanwendungen gesammelt und generiert werden. Das Data Warehouse wendet ein vordefiniertes Schema auf die Daten an, bevor es sie speichert. Sie müssen die Daten organisieren und ordnen, bevor Sie sie im Data Warehouse speichern.
Data Warehouses werden zur Speicherung großer Mengen strukturierter Daten aus Produktionssystemen verwendet, die regelmäßig analysiert werden müssen oder zur Erstellung regelmäßiger Berichte dienen. Data Warehouses sind in der Regel die "Quelle der Wahrheit" des Unternehmens, da sie organisierte und klassifizierte historische Daten speichern.
Data Lakes speichern Daten aus vielen Quellen, darunter auch unstrukturierte Quellen wie Protokolldaten, IoT-Sensoren (Internet of Things) und Social Media Feeds. Eine Data-Lake-Plattform ist im Grunde eine Sammlung von Rohdaten, die aus dem Geschäftsbetrieb eines Unternehmens und anderen internen und externen Quellen stammen.
Die Daten in einem Data Lake sind sehr heterogen und müssen möglicherweise zusätzlich verarbeitet werden, um nützlich zu sein, was sie für den durchschnittlichen Business-Analytics-Anwender ungeeignet macht. Für anspruchsvollere Nutzer wie Data Scientists und fortgeschrittene Datenanalysten können Data Lakes jedoch äußerst nützlich sein.
Die folgenden Best Practices können Ihnen helfen, einen Data Lake in Ihrem Unternehmen besser zu nutzen:
Data Governance und Access Control
Data Lakes werfen große Sicherheitsbedenken auf, da sie viele verschiedene Datentypen enthalten, von denen einige sensibel sein können oder Compliance-Anforderungen unterliegen. Da es keine Datenbanktabellen gibt, sind die Berechtigungen fließender und schwieriger einzurichten und müssen auf spezifischen Objekten oder Metadatendefinitionen basieren.
Heutzutage kann dieses Problem jedoch leicht gelöst werden, und es können verschiedene Governance-Tools verwendet werden, um zu kontrollieren, wer Zugriff auf die Daten hat. Mit Datenkataloglösungen können Benutzer einen Katalog der Daten erstellen, in dem verschiedene Datentypen und die Zugriffskontrollen und Speicherrichtlinien für jeden einzelnen festgelegt werden.
Mehrere Kopien von Daten speichern
Einer der Hauptgründe für die Einführung eines Data Lakes ist die Speicherung unstrukturierter Daten und die Trennung von Speicherung und Datenverarbeitung, so dass Sie mit relativ geringen Investitionen große Datenmengen speichern können. Data Lakes werden in der Regel zur Speicherung von Rohdaten und verarbeiteten Daten verwendet. Zusätzlich zu diesen historischen Daten gibt es Daten, die verarbeitet wurden und in analytischen Workflows verwendet wurden. Diese Daten müssen ebenfalls gespeichert werden, um zukünftige Analysen zu ermöglichen und als Grundlage für Berichte und Dashboards zu dienen.
Ein Data Lake ermöglicht es Ihnen, mehrere Kopien Ihrer Daten zu speichern, von denen jede andere Verwendungsmöglichkeiten haben kann.
Festlegung einer Aufbewahrungsrichtlinie
Ein Data Lake speichert in der Regel historische Daten, aber keine Daten sollten für immer gespeichert werden. Daten müssen entsorgt werden, wenn sie nicht mehr benötigt werden, sowohl um Speicherplatz zu sparen, als auch aufgrund der Anforderungen von Compliance-Standards wie der EU GDPR, California CCPA und Australian APP.
Es muss eine bequeme technische Methode geben, um die Daten, die gelöscht werden sollen, von den Daten zu trennen, die man behalten möchte. Das Auffinden der Daten in der Data Lake-Speicherarchitektur, die Speicherdienste wie Amazon S3, HDFS und Blockspeichergeräte umfassen kann, kann eine Herausforderung darstellen. Datenkataloglösungen können auch bei dieser Herausforderung helfen, indem sie eine zentrale Schnittstelle bereitstellen, über die Daten nach gewünschten Aufbewahrungsfristen klassifiziert werden können.
Imperva bietet Aktivitätsüberwachung für relationale Datenbanken, Data Warehouses und Data Lakes und generiert Echtzeitwarnungen zu anomalen Aktivitäten und Richtlinienverletzungen.
Zusätzlich zur Data Lake Security schützt Imperva alle Cloud-basierten Datenspeicher, um die Einhaltung von Vorschriften zu gewährleisten und die Flexibilität und Kostenvorteile Ihrer Cloud-Investitionen zu erhalten.
Die Fähigkeiten von Imperva umfassen:
- Sicherheit von Cloud-Daten – Vereinfachen Sie die Sicherung Ihrer Cloud-Datenbanken, um mit DevOps mitzuhalten. Die Lösung von Imperva ermöglicht es Nutzern von Cloud-verwalteten Diensten, schnell Transparenz und Kontrolle über Cloud-Daten zu erlangen.
- Datenbank-Sicherheit – Imperva bietet Analysen, Schutz und Reaktionsmöglichkeiten für Ihre Datenbestände, sowohl vor Ort als auch in der Cloud, und verschafft Ihnen die Risikotransparenz, die Sie benötigen, um Datenschutzverletzungen zu verhindern und Compliance-Vorfälle zu vermeiden. Integrieren Sie die Lösung in jede Datenbank, um sofortigen Einblick zu erhalten, universelle Richtlinien zu implementieren und die Zeit bis zur Wertschöpfung zu verkürzen.
- Datenrisikoanalyse - Automatisieren Sie die Erkennung von nicht konformem, risikoreichem oder bösartigem Datenzugriffsverhalten in allen Ihren Datenbanken im gesamten Unternehmen, um Abhilfemaßnahmen zu beschleunigen.
Unser zertifizieren Softprom-Spezialisten beraten Sie gerne persönlich zu den Lösung von Imperva
Softprom ist der Value Added Distributor von Imperva in Deutschland und Österreich.
Teilen:


