



Безопасность озера данных с помощью Imperva
News | 25.07.2023
Озеро данных представляет собой центральное хранилище, используемое для хранения нескольких типов данных в масштабе. Например, в озере данных можно хранить как неструктурированные, так и структурированные данные.
Озеро данных не требует предварительной работы с данными. Вы можете просто интегрировать и хранить данные по мере их поступления из различных источников. В зависимости от возможностей используемой системы можно настроить ввод данных в режиме реального времени.
Обычно организации используют озеро данных для хранения данных для будущего анализа или анализа в реальном времени. Для этого часто требуется использование инструментов и платформ аналитики, таких как Google BigQuery, Amazon Athena или Apache Spark.
Озеро данных может иметь различные типы физической архитектуры, поскольку оно может быть реализовано с использованием множества различных технологий. Однако есть три основных принципа, которые отличают озеро данных от других методов хранения больших данных:
- Все данные принимаются в озеро данных — оно принимает и архивирует данные из нескольких источников, включая структурированные, неструктурированные, необработанные и обработанные данные.
- Данные хранятся в исходном виде — после получения данных из источника данные хранятся непреобразованными или с минимальной обработкой.
- Данные преобразуются по требованию (on demand) — данные преобразуются и структурируются в соответствии с требованиями анализа и выполняемыми запросами.
Большая часть данных в озере данных неструктурирована и не предназначена для ответов на конкретные вопросы, но они хранятся таким образом, чтобы облегчить динамические запросы и анализ.
Независимо от того, как вы решите реализовать озеро данных, следующие возможности помогут вам поддерживать его работоспособность и эффективно использовать содержащиеся в нем неструктурированные данные:
- Классификация и профилирование данных - озеро данных должно позволять классифицировать данные по типам, содержанию, сценариям использования и возможным группам пользователей. Оно должно быть оснащено технологией профилирования данных, позволяющей получить представление о качестве данных.
- Соглашения - озеро данных должно, по возможности, обеспечивать применение согласованных типов файлов и соглашений об именах.
- Доступ к данным - должен быть стандартизирован процесс доступа к данным, используемый как человеческими пользователями, так и интегрированными системами, что позволяет отслеживать доступ и использование данных.
- Каталогизация данных - озеро данных должно предоставлять каталог данных, обеспечивающий поиск и извлечение данных в соответствии с их типом или сценарием использования.
- Защита данных - должны быть предусмотрены средства контроля безопасности, шифрования данных, автоматического мониторинга, а также оповещения о несанкционированном доступе к данным или подозрительных действиях авторизованных пользователей.
- Управление данными - наличие четких политик, доведенных до сведения всех сотрудников, касающихся навигации и использования озера данных, обеспечения качества данных и этики использования конфиденциальных данных.
Аналитика озера данных позволяет выполнять анализ больших объемов данных по запросу. Вы можете получать ценную информацию из данных, не требуя сложной инфраструктуры для предварительной обработки и организации ваших данных.
Вот несколько распространенных вариантов применения аналитики озера данных:
- Интерактивная аналитика - получение конкретных выводов из данных непосредственно из озера данных с помощью высокопроизводительного механизма запросов, например Google BigQuery или Amazon Athena.
- Обработка больших данных - анализ больших объемов данных с помощью таких инструментов, как Spark или Hadoop.
- Аналитика в реальном времени - обработка потоков данных, поступающих в озеро данных в режиме, близком к реальному времени, с использование таких инструментов обработки потоков, как Apache Kafka.
- Оперативная аналитика - поиск, фильтрация и визуализация данных из журналов и оперативных данных, таких как журналы веб-аналитики или Интернета вещей (IoT), с помощью таких инструментов, как Elasticsearch.
Хранилище данных или озеро данных – что выбрать?
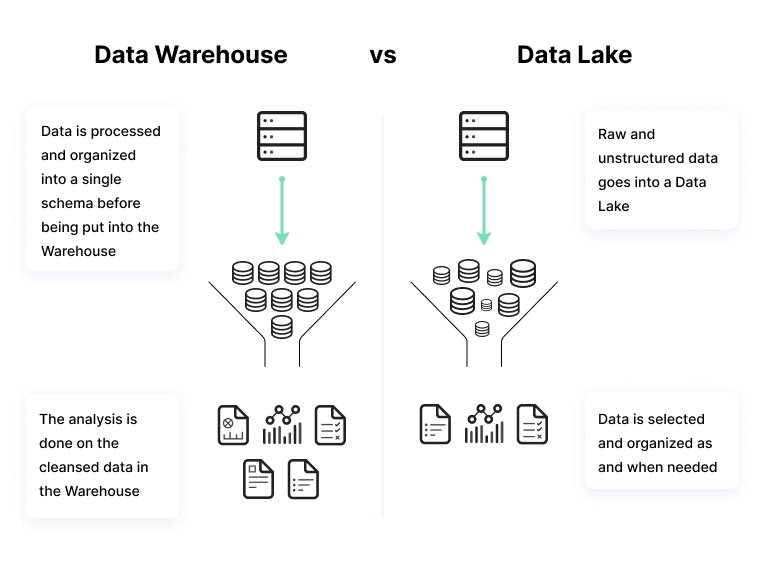
Хранилище данных - это хранилище данных, собираемых и генерируемых бизнес-приложениями. Хранилище данных применяет к данным предопределенную схему перед их хранением. Перед хранением данных в хранилище их необходимо упорядочить и систематизировать.
Хранилище данных используются для хранения больших объемов структурированных данных из производственных систем, которые необходимо регулярно анализировать или использовать для подготовки периодических отчетов. Хранилища данных обычно являются «источником истины» в организации, поскольку в них хранятся упорядоченные и классифицированные исторические данные.
Озеро данных хранит данные из многих источников, включая неструктурированные источники, такие как журнальные данные, датчики Интернета вещей (IoT) и ленты социальных сетей. Платформа озера данных - это, по сути, совокупность необработанных данных, поступающих из бизнес-операций организации и других источников, как внутренних, так и внешних.
Данные в озере данных крайне неоднородны и могут требовать дополнительной обработки для того, чтобы быть полезными, что делает их непригодными для рядового пользователя бизнес-аналитики. Однако озеро данных может быть чрезвычайно полезно для более сложных пользователей, таких как специалисты по обработке и анализу данных и опытные аналитики данных.
Рекомендации Imperva для эффективного использования озера данных в организации:
Управление данными и контроль доступа
Озеро данных может создать серьезные проблемы с безопасностью, поскольку содержит множество различных типов данных, некоторые из которых могут быть конфиденциальными или соответствовать нормативным требованиям. Поскольку в нем нет таблиц базы данных, права доступа более подвижны и сложны в настройке и должны основываться на конкретных объектах или определениях метаданных.
Однако сегодня эту проблему можно легко решить, и можно использовать различные инструменты управления, чтобы контролировать, кто имеет доступ к данным. Решения для каталогизации данных позволяют пользователям создавать каталог данных, определяя различные типы данных, а также элементы управления доступом и политики хранения для каждого из них.
Хранение нескольких копий данных
Одна из основных причин внедрения озера данных заключается в том, что оно хранит неструктурированные данные и отделяет хранение от вычислений, что позволяет хранить большие объемы данных при относительно небольших инвестициях. Озеро данных обычно используется для хранения как необработанных, так и обработанных данных. Часто возникает необходимость сохранить исторические данные в исходном формате. В дополнение к этим историческим данным есть данные, которые подверглись обработке и использовались в аналитических рабочих процессах. Эти данные также должны быть сохранены для последующего анализа и в качестве основы для отчетов и информационных панелей.
Озеро данных позволяет хранить несколько копий данных, каждая из которых может иметь свое потенциальное применение.
Политика хранения
Озеро данных обычно хранит исторические данные, но никакие данные не должны храниться вечно. Данные должны быть удалены, когда они больше не нужны, как для экономии места, так и в соответствии с требованиями стандартов соответствия, таких как GDPR ЕС, CCPA штата Калифорния или австралийский APP.
Должен существовать удобный технический метод для отделения данных, которые вы хотите удалить, от данных, которые вы хотите сохранить.
Решения Imperva обеспечивают мониторинг активности реляционных баз данных, хранилищ данных и озера данных, генерируя в режиме реального времени предупреждения об аномальной активности и нарушениях политик.
В дополнение к безопасности озера данных Imperva защищает все облачные хранилища данных, обеспечивая соответствие нормативным требованиям и сохраняя гибкость и экономическую эффективность инвестиций в облако.
Возможности решений Imperva:
- Защита облачных данных (Cloud Data Security): Упростите защиту облачных баз данных, чтобы не отставать от DevOps. Решение Imperva позволяет пользователям облачных сервисов быстро получить видимость и контроль над облачными данными.
- Безопасность баз данных (Database Security): Imperva обеспечивает аналитику, защиту и реагирование на все ваши информационные активы, как локальные, так и облачные, что позволяет предотвратить утечку данных и избежать инцидентов, связанных с нарушением нормативных требований. Интеграция с любой базой данных позволяет получить мгновенный обзор, внедрить универсальные политики и ускорить окупаемость.
- Анализ риска данных (Data Risk Analysis): Автоматизируйте обнаружение несоответствующего, рискованного или злонамеренного доступа к данным во всех ваших базах данных в масштабе предприятия, чтобы ускорить восстановление.
Обращайтесь за персональной консультацией по решениям Imperva к специалистам Softprom.
Softprom - Value Added Distributor Imperva.
Поделиться:


